データウェアハウスの連携
この記事では、Braze のクラウドデータ取り込み (CDI) を使用して、関連するデータを Snowflake、Redshift、BigQuery、および Databricks の連携と同期する方法について説明します。
製品の設定
クラウドデータ取り込みの連携では、Braze 側とインスタンスで設定がいくつか必要です。次のステップに従って、連携を設定します。
- Snowflake インスタンスで、Braze と同期するテーブルまたはビューを設定します。
- Braze ダッシュボードで新しい連携を作成します。
- Braze ダッシュボードに表示された公開キーを取得し、認証用として Snowflake ユーザーに公開キーを追加します。
- 連携のテストを行い、同期を開始します。
- 同期する Redshift テーブルへの Braze のアクセスが許可されていることを確認します。Braze はインターネット経由で Redshift に接続します。
- Redshift インスタンスで、Braze と同期するテーブルまたはビューを設定します。
- Braze ダッシュボードで新しい連携を作成します。
- 連携のテストを行い、同期を開始します。
- サービスアカウントを作成し、同期するデータを含む BigQuery のプロジェクトとデータセットへのアクセスを許可します。
- BigQuery アカウントで、Braze と同期するテーブルまたはビューを設定します。
- Braze ダッシュボードで新しい連携を作成します。
- 連携のテストを行い、同期を開始します。
- サービスアカウントを作成し、同期するデータを含む Databricks のプロジェクトとデータセットへのアクセスを許可します。
- Databricks アカウントで、Braze と同期するテーブルまたはビューを設定します。
- Braze ダッシュボードで新しい連携を作成します。
- 連携のテストを行い、同期を開始します。
Braze が Classic および Pro の SQL インスタンスに接続するときにウォームアップ時間が 2 〜 5 分かかることがあるため、接続の設定中やテスト中、およびスケジュールされた同期の開始時に遅延が発生します。サーバーレス SQL インスタンスを使用すると、ウォームアップ時間が最小限に抑えられ、クエリのスループットが向上しますが、連携コストが若干高くなる場合があります。
ステップ 1: テーブルまたはビューの設定
ステップ 1: テーブルの設定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CREATE DATABASE BRAZE_CLOUD_PRODUCTION;
CREATE SCHEMA BRAZE_CLOUD_PRODUCTION.INGESTION;
CREATE OR REPLACE TABLE BRAZE_CLOUD_PRODUCTION.INGESTION.USERS_ATTRIBUTES_SYNC (
UPDATED_AT TIMESTAMP_NTZ(9) NOT NULL DEFAULT SYSDATE(),
--at least one of external_id, alias_name and alias_label, email, phone, or braze_id is required
EXTERNAL_ID VARCHAR(16777216),
--if using user alias, both alias_name and alias_label are required
ALIAS_LABEL VARCHAR(16777216),
ALIAS_NAME VARCHAR(16777216),
--braze_id can only be used to update existing users created through the Braze SDK
BRAZE_ID VARCHAR(16777216),
--If you include both email and phone, we will use the email as the primary identifier
EMAIL VARCHAR(16777216),
PHONE VARCHAR(16777216),
PAYLOAD VARCHAR(16777216) NOT NULL
);
データベース、スキーマ、テーブルには任意の名前を付けることができますが、列名は先行する定義と一致する必要があります。
UPDATED_AT- テーブルで、この行が更新された時刻、または追加された時刻。最後の同期以降に追加されたか、更新された行のみを同期します。- ユーザー識別子の列。テーブルには、ユーザー識別子列が 1 列以上含まれている場合があります。各行は、識別子 (
external_id単独か、alias_nameとalias_labelまたはbraze_idの組み合わせ) を 1 つのみ含まなければなりません。ソーステーブルには、1 つ、2 つ、または 3 つすべての識別子タイプの列が含まれる場合があります。EXTERNAL_ID- 更新対象のユーザーを特定します。これは Braze で使用されているexternal_id値と一致しなければなりません。ALIAS_NAMEおよびALIAS_LABEL- この 2 列はユーザーエイリアスオブジェクトを作成します。alias_nameは一意の識別子である必要があり、alias_labelはエイリアスのタイプを指定します。ユーザーは、異なるラベルを持つ複数のエイリアスを持つことができますが、alias_labelごとにalias_nameを 1 つしか持つことができません。BRAZE_ID- Braze のユーザー識別子。これは Braze SDK によって生成されます。クラウドデータ取り込み経由で Braze ID を使用して新規ユーザーを作成することはできません。新規ユーザーを作成するには、外部ユーザー ID またはユーザーエイリアスを指定します。EMAIL- ユーザーのメールアドレス。同じメールアドレスを持つプロファイルが複数存在する場合、最後に更新されたプロファイルが優先されて更新されます。メールと電話の両方が指定された場合は、メールをプライマリ識別子として使用します。PHONE- ユーザーのメールアドレス。同じ電話番号を持つプロファイルが複数存在する場合、最後に更新されたプロファイルが優先されて更新されます。
PAYLOAD- Braze 内のユーザーと同期するフィールドの JSON 文字列。
ステップ 2: ロールとデータベース権限の設定
```json CREATE ROLE BRAZE_INGESTION_ROLE;
GRANT USAGE ON DATABASE BRAZE_CLOUD_PRODUCTION TO ROLE BRAZE_INGESTION_ROLE; GRANT USAGE ON SCHEMA BRAZE_CLOUD_PRODUCTION.INGESTION TO ROLE BRAZE_INGESTION_ROLE; GRANT SELECT ON TABLE BRAZE_CLOUD_PRODUCTION.INGESTION.USERS_ATTRIBUTES_SYNC TO ROLE BRAZE_INGESTION_ROLE; ```
必要に応じて名前を更新します。ただし、権限は前述の例と一致する必要があります。
ステップ 3: ウェアハウスの設定と、Braze ロールへのアクセス権の付与
```json CREATE WAREHOUSE BRAZE_INGESTION_WAREHOUSE;
GRANT USAGE ON WAREHOUSE BRAZE_INGESTION_WAREHOUSE TO ROLE BRAZE_INGESTION_ROLE; ```
ウェアハウスの自動再開フラグをオンにする必要があります。オンにしない場合は、Braze がクエリの実行時にオンにできるように、Braze に追加の OPERATE 権限を付与する必要があります。
ステップ4: ユーザーの設定
```json CREATE USER BRAZE_INGESTION_USER;
GRANT ROLE BRAZE_INGESTION_ROLE TO USER BRAZE_INGESTION_USER; ```
このステップの後、Braze と接続情報を共有し、ユーザーに追加する公開キーを受け取ります。
異なるワークスペースを同じ Snowflake アカウントに接続する場合は、連携を作成する Braze ワークスペースごとに一意のユーザーを作成する必要があります。ワークスペース内では、複数の連携にわたって同じユーザーを再利用できますが、同じ Snowflake アカウントのユーザーが複数のワークスペースで重複すると、連携の作成に失敗します。
ステップ 5: Snowflake ネットワークポリシー内で Braze IP を許可 (任意)
Snowflake アカウントの設定によっては、Snowflake のネットワークポリシー内で以下の IP アドレスを許可する必要があります。これを有効にする方法の詳細については、ネットワークポリシーの変更に関する Snowflake の関連ドキュメントを参照してください。
インスタンス US-01、US-02、US-03、US-04、US-05、US-06、US-07 の場合 |
インスタンス EU-01 および EU-02 の場合 |
|---|---|
23.21.118.191 |
52.58.142.242 |
34.206.23.173 |
52.29.193.121 |
50.16.249.9 |
35.158.29.228 |
52.4.160.214 |
18.157.135.97 |
54.87.8.34 |
3.123.166.46 |
54.156.35.251 |
3.64.27.36 |
52.54.89.238 |
3.65.88.25 |
18.205.178.15 |
3.68.144.188 |
3.70.107.88 |
ステップ 1: テーブルの設定
オプションで、ソーステーブルを保持する新規データベースとスキーマを設定します。
1
2
CREATE DATABASE BRAZE_CLOUD_PRODUCTION;
CREATE SCHEMA BRAZE_CLOUD_PRODUCTION.INGESTION;
CDI 連携に使用するテーブル (またはビュー) を作成します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
CREATE TABLE BRAZE_CLOUD_PRODUCTION.INGESTION.USERS_ATTRIBUTES_SYNC (
updated_at timestamptz default sysdate,
--at least one of external_id, alias_name and alias_label, or braze_id is required
external_id varchar,
--if using user alias, both alias_name and alias_label are required
alias_label varchar,
alias_name varchar,
--braze_id can only be used to update existing users created through the Braze SDK
braze_id varchar,
--If you include both email and phone, we will use the email as the primary identifier
email varchar,
phone varchar,
payload varchar(max)
)
データベース、スキーマ、テーブルには任意の名前を付けることができますが、列名は先行する定義と一致する必要があります。
UPDATED_AT- テーブルで、この行が更新された時刻、または追加された時刻。最後の同期以降に追加されたか、更新された行のみを同期します。- ユーザー識別子の列。テーブルには、ユーザー識別子列が 1 列以上含まれている場合があります。各行は、識別子 (
external_id単独か、alias_nameとalias_labelまたはbraze_idの組み合わせ) を 1 つのみ含まなければなりません。ソーステーブルには、1 つ、2 つ、または 3 つすべての識別子タイプの列が含まれる場合があります。EXTERNAL_ID- 更新対象のユーザーを特定します。これは Braze で使用されているexternal_id値と一致しなければなりません。ALIAS_NAMEおよびALIAS_LABEL- この 2 列はユーザーエイリアスオブジェクトを作成します。alias_nameは一意の識別子である必要があり、alias_labelはエイリアスのタイプを指定します。ユーザーは、異なるラベルを持つ複数のエイリアスを持つことができますが、alias_labelごとにalias_nameを 1 つしか持つことができません。BRAZE_ID- Braze のユーザー識別子。これは Braze SDK によって生成されます。クラウドデータ取り込み経由で Braze ID を使用して新規ユーザーを作成することはできません。新規ユーザーを作成するには、外部ユーザー ID またはユーザーエイリアスを指定します。EMAIL- ユーザーのメールアドレス。同じメールアドレスを持つプロファイルが複数存在する場合、最後に更新されたプロファイルが優先されて更新されます。メールと電話の両方が指定された場合は、メールをプライマリ識別子として使用します。PHONE- ユーザーのメールアドレス。同じ電話番号を持つプロファイルが複数存在する場合、最後に更新されたプロファイルが優先されて更新されます。
PAYLOAD- Braze 内のユーザーと同期するフィールドの JSON 文字列。
ステップ 2: ユーザーの作成と権限の付与
1
2
3
CREATE USER braze_user PASSWORD '{password}';
GRANT USAGE ON SCHEMA BRAZE_CLOUD_PRODUCTION.INGESTION to braze_user;
GRANT SELECT ON TABLE USERS_ATTRIBUTES_SYNC TO braze_user;
これらは、このユーザーに最低限必要な権限です。CDI 連携を複数作成する場合は、スキーマに権限を付与したり、グループを使用して権限を管理したりできます。
ステップ 3: Braze IP へのアクセスの許可
ファイアウォールや他のネットワークポリシーがある場合は、Redshift インスタンスに Braze ネットワークへのアクセスを許可する必要があります。Braze ダッシュボードの地域に対応する以下の IP からのアクセスを許可します。
また、Redshift のデータへのアクセスを Braze に許可するように、セキュリティグループを変更しなければならないこともあります。以下の IP と Redshift クラスターのクエリに使用するポート (デフォルトは 5439) のインバウンドトラフィックを明示的に許可してください。インバウンドルールが「すべて許可」に設定されている場合でも、このポートで Redshift TCP 接続を明示的に許可する必要があります。さらに、Braze がクラスターに接続するために、Redshift クラスターのエンドポイントがパブリックにアクセス可能であることが重要です。
Redshift クラスターにパブリックアクセスを許可しない場合は、ssh トンネルを使用して Redshift データにアクセスするように VPC と EC2 インスタンスを設定できます。詳細については、この AWS ナレッジセンターの投稿を参照してください。
インスタンス US-01、US-02、US-03、US-04、US-05、US-06、US-07 の場合 |
インスタンス EU-01 および EU-02 の場合 |
|---|---|
23.21.118.191 |
52.58.142.242 |
34.206.23.173 |
52.29.193.121 |
50.16.249.9 |
35.158.29.228 |
52.4.160.214 |
18.157.135.97 |
54.87.8.34 |
3.123.166.46 |
54.156.35.251 |
3.64.27.36 |
52.54.89.238 |
3.65.88.25 |
18.205.178.15 |
3.68.144.188 |
3.70.107.88 |
ステップ 1: テーブルの設定
オプションで、ソーステーブルを保持する新規のプロジェクトまたはデータセットを設定します。
次のフィールドを持ち、CDI 連携に使用するテーブルを 1 つ以上作成します。
| フィールド名 | タイプ | モード |
|---|---|---|
UPDATED_AT |
タイムスタンプ | 必須 |
PAYLOAD |
JSON | 必須 |
EXTERNAL_ID |
文字列 | 省略 (NULL) 可 |
ALIAS_NAME |
文字列 | 省略 (NULL) 可 |
ALIAS_LABEL |
文字列 | 省略 (NULL) 可 |
BRAZE_ID |
文字列 | 省略 (NULL) 可 |
EMAIL |
文字列 | 省略 (NULL) 可 |
PHONE |
文字列 | 省略 (NULL) 可 |
プロジェクト、データセット、テーブルには任意の名前を付けることができますが、列名は先行する定義と一致する必要があります。
UPDATED_AT- テーブルで、この行が更新された時刻、または追加された時刻。最後の同期以降に追加されたか、更新された行のみを同期します。- ユーザー識別子の列。テーブルには、ユーザー識別子列が 1 列以上含まれている場合があります。各行は、識別子 (
external_idか、alias_nameとalias_labelまたはbraze_idの組み合わせ) を 1 つのみ含まなければなりません。ソーステーブルには、1 つ、2 つ、または 3 つすべての識別子タイプの列が含まれる場合があります。EXTERNAL_ID- 更新対象のユーザーを特定します。これは Braze で使用されているexternal_id値と一致しなければなりません。ALIAS_NAMEおよびALIAS_LABEL- この 2 列はユーザーエイリアスオブジェクトを作成します。alias_nameは一意の識別子である必要があり、alias_labelはエイリアスのタイプを指定します。ユーザーは、異なるラベルを持つ複数のエイリアスを持つことができますが、alias_labelごとにalias_nameを 1 つしか持つことができません。BRAZE_ID- Braze のユーザー識別子。これは Braze SDK によって生成されます。クラウドデータ取り込み経由で Braze ID を使用して新規ユーザーを作成することはできません。新規ユーザーを作成するには、外部ユーザー ID またはユーザーエイリアスを指定します。EMAIL- ユーザーのメールアドレス。同じメールアドレスを持つプロファイルが複数存在する場合、最後に更新されたプロファイルが優先されて更新されます。メールと電話の両方が指定された場合は、メールをプライマリ識別子として使用します。PHONE- ユーザーのメールアドレス。同じ電話番号を持つプロファイルが複数存在する場合、最後に更新されたプロファイルが優先されて更新されます。 email varchar, phone_number varchar,
PAYLOAD- Braze 内のユーザーと同期するフィールドの JSON 文字列。
ステップ 2: サービスアカウントの作成と権限の付与
GCP で、Braze がテーブルに接続してデータを読み取るために使用するサービスアカウントを作成します。サービスアカウントには次の権限が必要です。
- BigQuery 接続ユーザー: Braze に接続を許可します。
- BigQuery ユーザー: クエリの実行、データセットメタデータの読み取り、およびテーブルの一覧表示を行うためのアクセスを Braze に提供します。
- BigQuery データビューアー: データセットとその内容を表示するためのアクセスを Braze に提供します。
- BigQuery ジョブユーザー: ジョブを実行するためのアクセスを Braze に提供します。
サービスアカウントを作成して権限を付与したら、JSON キーを生成します。その方法の詳細については、こちらを参照してください。これは後で Braze ダッシュボードに更新します。
ステップ 3: Braze IP へのアクセスの許可
ネットワークポリシーを設定している場合は、Braze に Big Query インスタンスへのネットワークアクセスを許可する必要があります。Braze ダッシュボードの地域に対応する以下の IP からのアクセスを許可します。
インスタンス US-01、US-02、US-03、US-04、US-05、US-06、US-07 の場合 |
インスタンス EU-01 および EU-02 の場合 |
|---|---|
23.21.118.191 |
52.58.142.242 |
34.206.23.173 |
52.29.193.121 |
50.16.249.9 |
35.158.29.228 |
52.4.160.214 |
18.157.135.97 |
54.87.8.34 |
3.123.166.46 |
54.156.35.251 |
3.64.27.36 |
52.54.89.238 |
3.65.88.25 |
18.205.178.15 |
3.68.144.188 |
3.70.107.88 |
ステップ 1: テーブルの設定
オプションで、ソーステーブルを保持する新規のプロジェクトまたはデータセットを設定します。
次のフィールドを持ち、CDI 連携に使用するテーブルを 1 つ以上作成します。
| フィールド名 | タイプ | モード |
|---|---|---|
UPDATED_AT |
タイムスタンプ | 必須 |
PAYLOAD |
文字列または構造体 | 必須 |
EXTERNAL_ID |
文字列 | 省略 (NULL) 可 |
ALIAS_NAME |
文字列 | 省略 (NULL) 可 |
ALIAS_LABEL |
文字列 | 省略 (NULL) 可 |
BRAZE_ID |
文字列 | 省略 (NULL) 可 |
EMAIL |
文字列 | 省略 (NULL) 可 |
PHONE |
文字列 | 省略 (NULL) 可 |
スキーマとテーブルには任意の名前を付けることができますが、列名は先行する定義と一致する必要があります。
UPDATED_AT- テーブルで、この行が更新された時刻、または追加された時刻。最後の同期以降に追加されたか、更新された行のみを同期します。- ユーザー識別子の列。テーブルには、ユーザー識別子列が 1 列以上含まれている場合があります。各行は、識別子 (
external_id単独か、alias_nameとalias_labelまたはbraze_idの組み合わせ) を 1 つのみ含まなければなりません。ソーステーブルには、1 つ、2 つ、または 3 つすべての識別子タイプの列が含まれる場合があります。EXTERNAL_ID- 更新対象のユーザーを特定します。これは Braze で使用されているexternal_id値と一致しなければなりません。ALIAS_NAMEおよびALIAS_LABEL- この 2 列はユーザーエイリアスオブジェクトを作成します。alias_nameは一意の識別子である必要があり、alias_labelはエイリアスのタイプを指定します。ユーザーは、異なるラベルを持つ複数のエイリアスを持つことができますが、alias_labelごとにalias_nameを 1 つしか持つことができません。BRAZE_ID- Braze のユーザー識別子。これは Braze SDK によって生成されます。クラウドデータ取り込み経由で Braze ID を使用して新規ユーザーを作成することはできません。新規ユーザーを作成するには、外部ユーザー ID またはユーザーエイリアスを指定します。EMAIL- ユーザーのメールアドレス。同じメールアドレスを持つプロファイルが複数存在する場合、最後に更新されたプロファイルが優先されて更新されます。メールと電話の両方が指定された場合は、メールをプライマリ識別子として使用します。PHONE- ユーザーのメールアドレス。同じ電話番号を持つプロファイルが複数存在する場合、最後に更新されたプロファイルが優先されて更新されます。
PAYLOAD- Braze でユーザーと同期するフィールドの文字列または構造体。
ステップ 2: アクセストークンの作成
Braze が Databricks にアクセスするには、パーソナルアクセストークンを作成する必要があります。
- Databricks ワークスペースで、上部バーにある Databricks ユーザー名をクリックし、ドロップダウンから [ユーザー設定] を選択します。
- [アクセストークン] タブで、[新しいトークンの生成] をクリックします。
- 「Braze CDI」など、このトークンの識別に役立つコメントを入力し、[有効期間 (日)] ボックスを空 (空白) のままにして、トークンの有効期間を有効期間なしに変更します。
- [生成] をクリックします。
- 表示されたトークンをコピーして、[完了] をクリックします。
認証情報の作成ステップで Braze ダッシュボードへの入力が必要になるまで、トークンを安全な場所に保管してください。
ステップ 3: Braze IP へのアクセスの許可
ネットワークポリシーを設定している場合は、Brazeに Databricks インスタンスへのネットワークアクセスを許可する必要があります。Braze ダッシュボードの地域に対応する以下の IP からのアクセスを許可します。
インスタンス US-01、US-02、US-03、US-04、US-05、US-06、US-07 の場合 |
インスタンス EU-01 および EU-02 の場合 |
|---|---|
23.21.118.191 |
52.58.142.242 |
34.206.23.173 |
52.29.193.121 |
50.16.249.9 |
35.158.29.228 |
52.4.160.214 |
18.157.135.97 |
54.87.8.34 |
3.123.166.46 |
54.156.35.251 |
3.64.27.36 |
52.54.89.238 |
3.65.88.25 |
18.205.178.15 |
3.68.144.188 |
3.70.107.88 |
ステップ 2: Braze ダッシュボードでの新規連携の作成
[パートナー連携] > [テクノロジーパートナー] に移動します。Snowflake のページを見つけて、[新しいインポート同期を作成] をクリックします。
古いナビゲーションを使用している場合は、[テクノロジーパートナー] に移動します。
ステップ 1: Snowflake の接続情報とソーステーブルの追加
Snowflake データウェアハウスとソーステーブルの情報を入力して、次のステップに進みます。
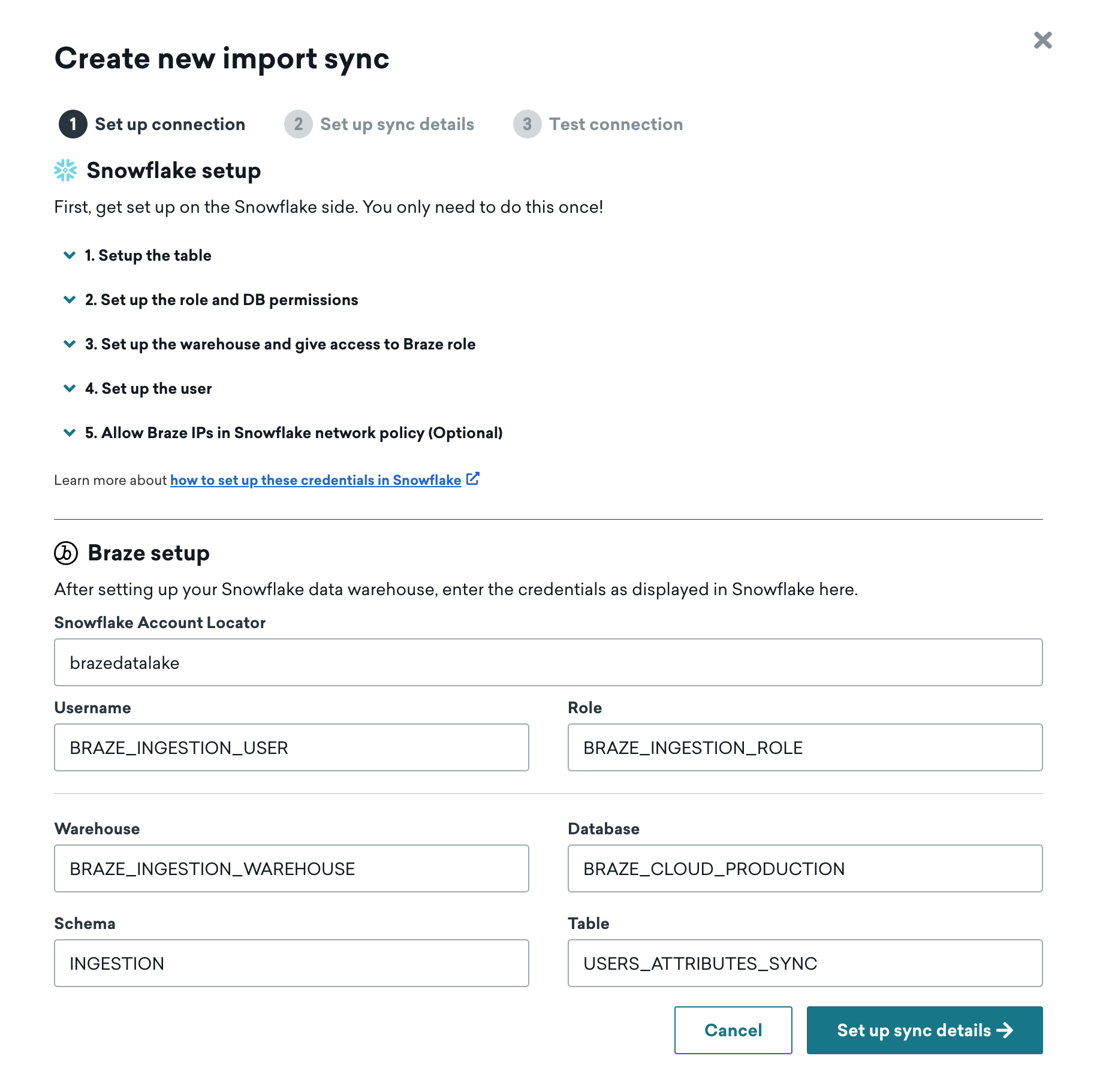
ステップ 2: 同期の詳細の設定
次に、同期の名前を選択し、連絡先のメールアドレスを入力します。この連絡先情報は、テーブルへのアクセスが予期せず削除されたなど、連携エラーの通知に使用されます。
連絡先のメールアドレスは、テーブルや権限の欠落など、グローバルまたは同期レベルのエラーの通知のみを受け取ります。行レベルの問題を受け取ることはありません。グローバルエラーは、同期の実行を妨げる接続の重大な問題を示します。このような問題として、次のようなものがあります。
- 接続の問題
- リソース不足
- 権限の問題
- (カタログ同期のみ) カタログ層の容量不足
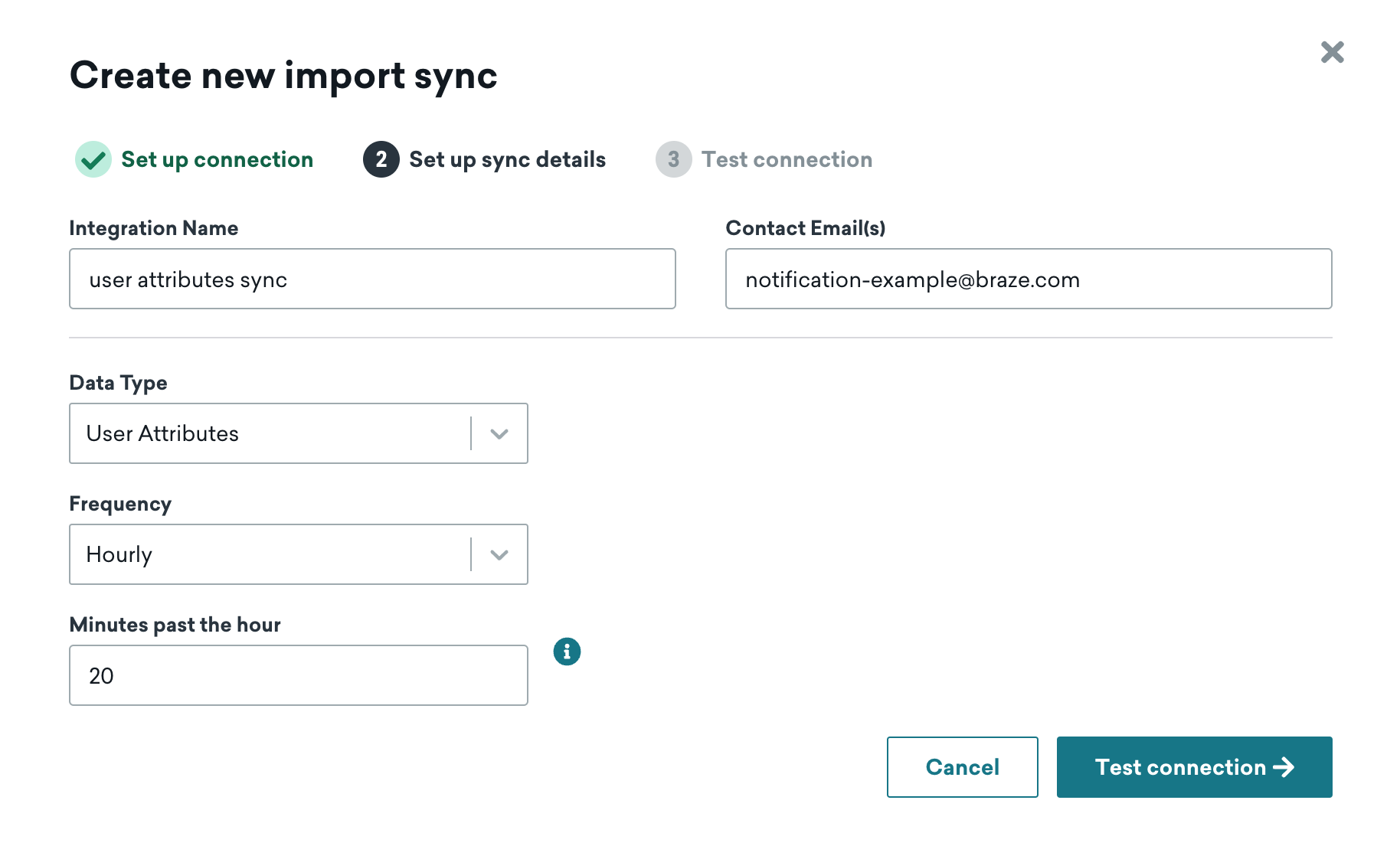
データ型と同期頻度も選択します。頻度の範囲は 15 分間隔から 1 か月に 1 回までです。Braze ダッシュボードで設定したタイムゾーンを使用して、定期的な同期がスケジュールされます。サポートされているデータ型は、カスタム属性、カスタムイベント、および購入イベントです。同期のデータ型は、作成後に変更できません。
Braze ユーザーへの公開キーの追加
この時点で、Snowflake に戻って設定を完了する必要があります。ダッシュボードに表示されている公開キーを、Snowflake に Braze を接続するために作成したユーザーに追加します。
その方法の詳細については、Snowflake のドキュメントを参照してください。任意の時点でのキーのローテーションを行う場合、新規のキーペアを生成して、新規の公開キーを提供できます。
1
ALTER USER BRAZE_INGESTION_USER SET rsa_public_key='Braze12345...';
[パートナー連携] > [テクノロジーパートナー] に移動します。Redshift のページを見つけて、[新しいインポート同期を作成] をクリックします。
古いナビゲーションを使用している場合は、[テクノロジーパートナー] に移動します。
ステップ 1: Redshift の接続情報とソーステーブルの追加
Redshift データウェアハウスとソーステーブルの情報を入力します。プライベートネットワークトンネルを使用している場合は、スライダーを切り替えてトンネル情報を入力します。その後、次のステップに進みます。
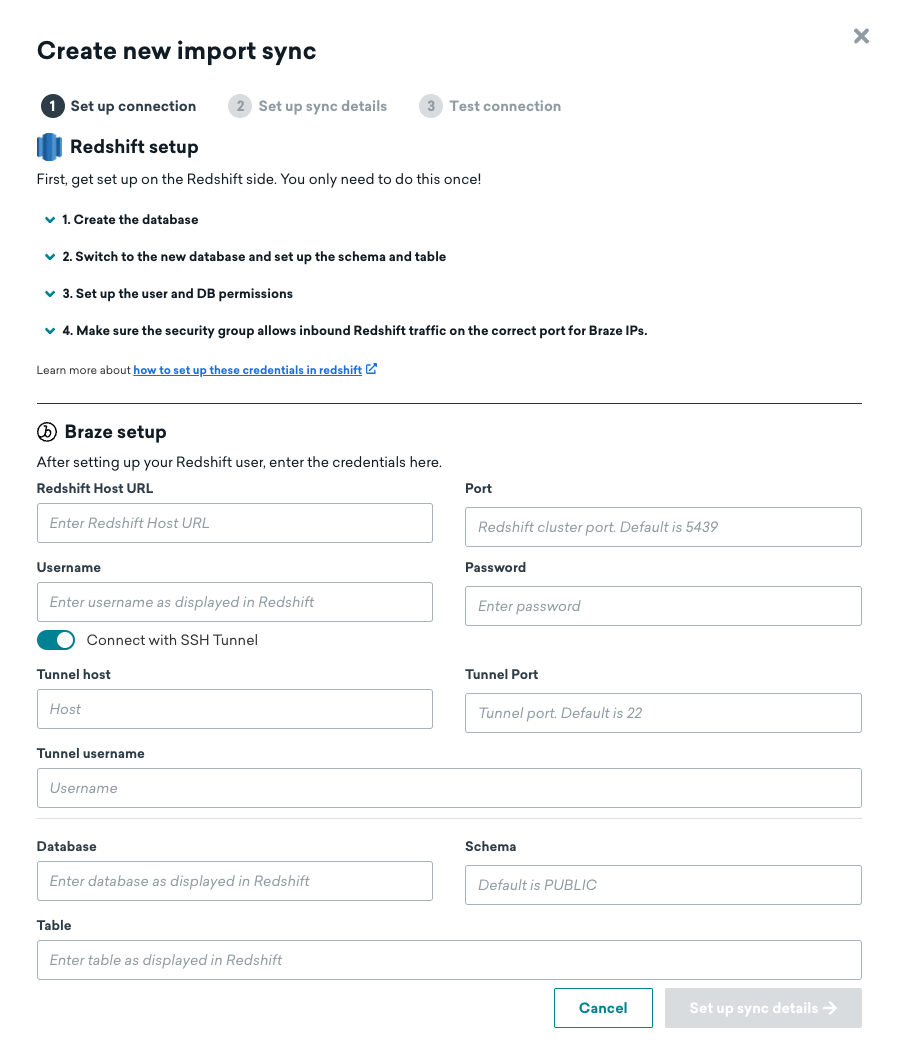
ステップ 2: 同期の詳細の設定
次に、同期の名前を選択し、連絡先のメールアドレスを入力します。この連絡先情報は、テーブルへのアクセスが予期せず削除されたなど、連携エラーの通知に使用されます。
連絡先のメールアドレスは、テーブルや権限の欠落など、グローバルまたは同期レベルのエラーの通知のみを受け取ります。行レベルの問題を受け取ることはありません。グローバルエラーは、同期の実行を妨げる接続の重大な問題を示します。このような問題として、次のようなものがあります。
- 接続の問題
- リソース不足
- 権限の問題
- (カタログ同期のみ) カタログ層の容量不足
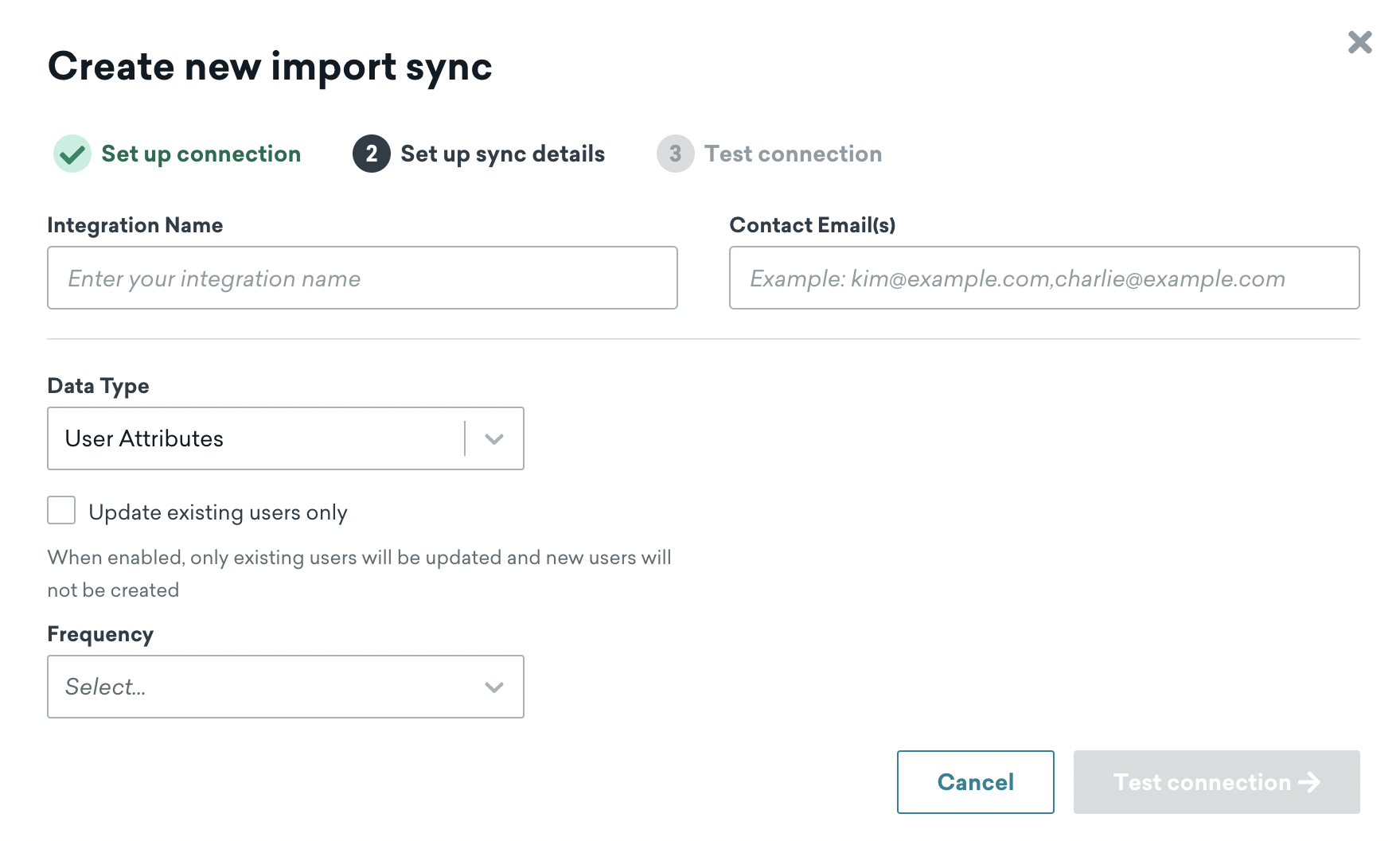
データ型と同期頻度も選択します。頻度の範囲は 15 分間隔から 1 か月に 1 回までです。Braze ダッシュボードで設定したタイムゾーンを使用して、定期的な同期がスケジュールされます。サポートされているデータ型は、カスタム属性、カスタムイベント、および購入イベントです。同期のデータ型は、作成後に変更できません。
[パートナー連携] > [テクノロジーパートナー] に移動します。BigQuery のページを見つけて、[新しいインポート同期を作成] をクリックします。
古いナビゲーションを使用している場合は、[テクノロジーパートナー] に移動します。
ステップ 1: BigQuery の接続情報とソーステーブルの追加
JSON キーをアップロードし、サービスアカウントの名前を入力して、ソーステーブルの詳細を入力します。
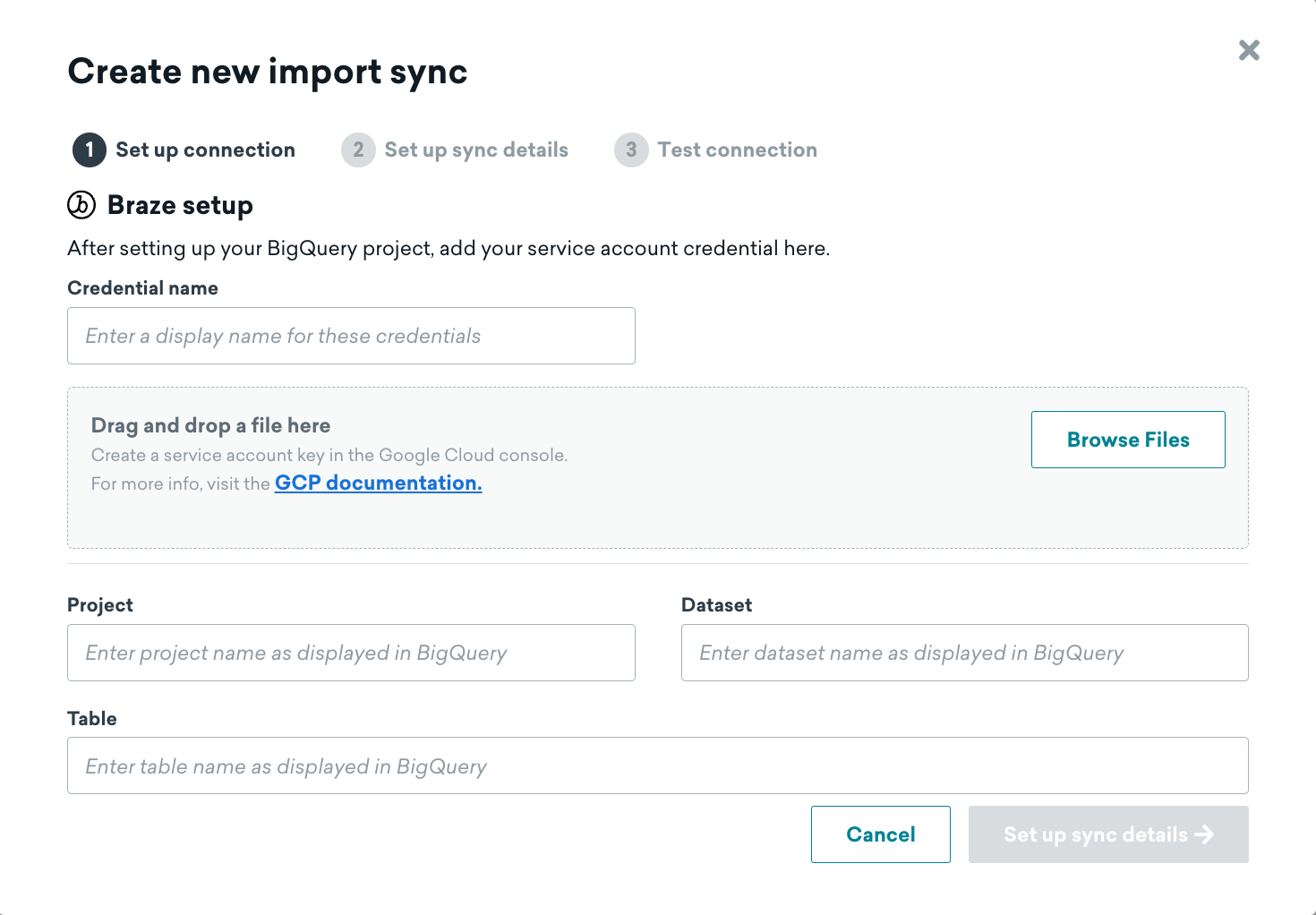
ステップ 2: 同期の詳細の設定
次に、同期の名前を選択し、連絡先のメールアドレスを入力します。この連絡先情報は、テーブルへのアクセスが予期せず削除されたなど、連携エラーの通知に使用されます。
連絡先のメールアドレスは、テーブルや権限の欠落など、グローバルまたは同期レベルのエラーの通知のみを受け取ります。行レベルの問題を受け取ることはありません。グローバルエラーは、同期の実行を妨げる接続の重大な問題を示します。このような問題として、次のようなものがあります。
- 接続の問題
- リソース不足
- 権限の問題
- (カタログ同期のみ) カタログ層の容量不足
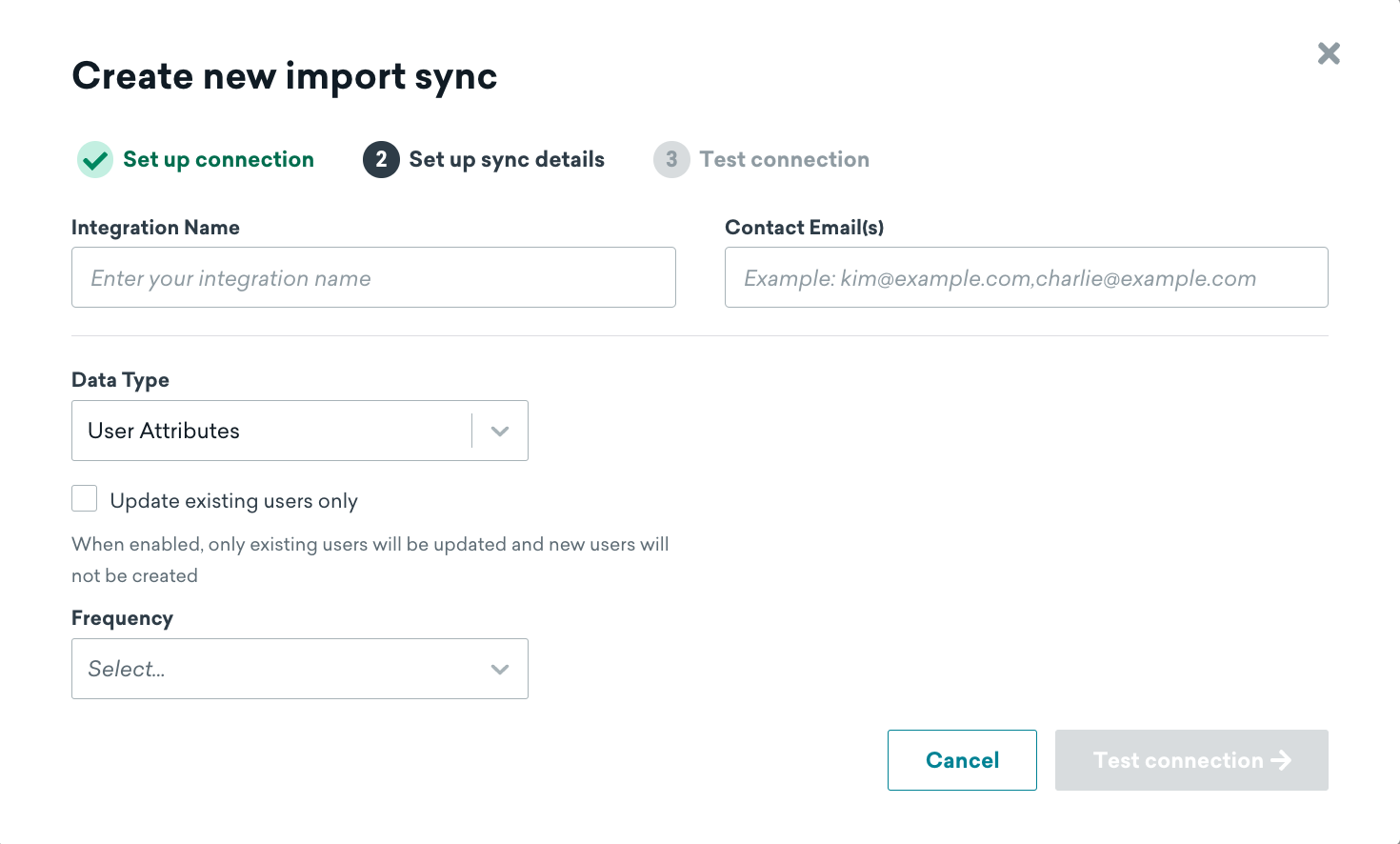
データ型と同期頻度も選択します。頻度の範囲は 15 分間隔から 1 か月に 1 回までです。Braze ダッシュボードで設定したタイムゾーンを使用して、定期的な同期がスケジュールされます。サポートされているデータ型は、カスタム属性、カスタムイベント、購入イベント、およびユーザー削除です。同期のデータ型は、作成後に変更できません。
[パートナー連携] > [テクノロジーパートナー] に移動します。Databricks のページを見つけて、[新しいインポート同期を作成] をクリックします。
古いナビゲーションを使用している場合は、[テクノロジーパートナー] に移動します。
ステップ 1: Databricks の接続情報とソーステーブルの追加
Databricks データウェアハウスとソーステーブルの情報を入力して、次のステップに進みます。
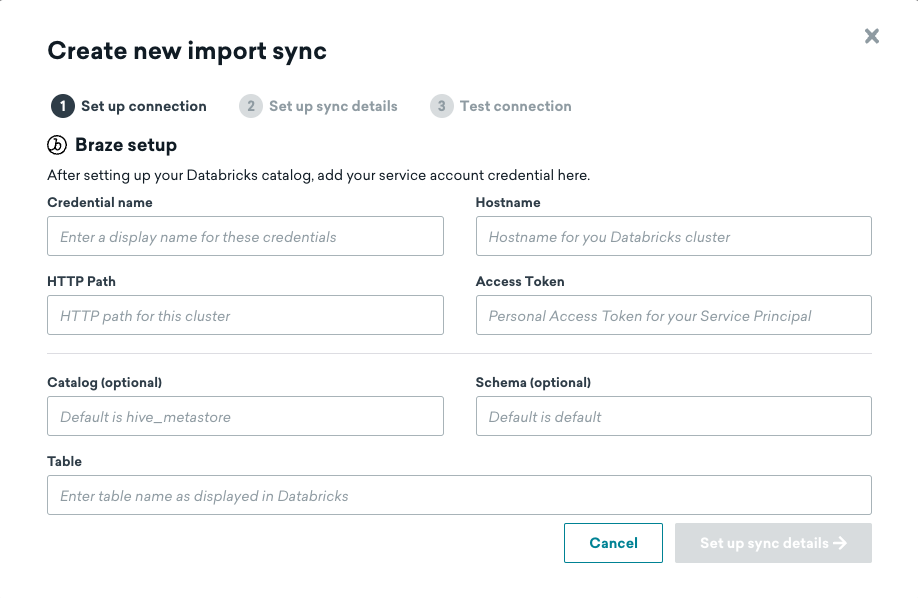
ステップ 2: 同期の詳細の設定
次に、同期の名前を選択し、連絡先のメールアドレスを入力します。この連絡先情報は、テーブルへのアクセスが予期せず削除されたなど、連携エラーの通知に使用されます。
連絡先のメールアドレスは、テーブルや権限の欠落など、グローバルまたは同期レベルのエラーの通知のみを受け取ります。行レベルの問題を受け取ることはありません。グローバルエラーは、同期の実行を妨げる接続の重大な問題を示します。このような問題として、次のようなものがあります。
- 接続の問題
- リソース不足
- 権限の問題
- (カタログ同期のみ) カタログ層の容量不足

データ型と同期頻度も選択します。頻度の範囲は 15 分間隔から 1 か月に 1 回までです。Braze ダッシュボードで設定したタイムゾーンを使用して、定期的な同期がスケジュールされます。サポートされているデータ型は、カスタム属性、カスタムイベント、購入イベント、およびユーザー削除です。同期のデータ型は、作成後に変更できません。
ステップ 3: テスト接続
Braze ダッシュボードに戻って、[テスト接続] をクリックします。成功すると、データのプレビューが表示されます。何らかの理由で接続できない場合、問題のトラブルシューティングに役立つエラーメッセージが表示されます。
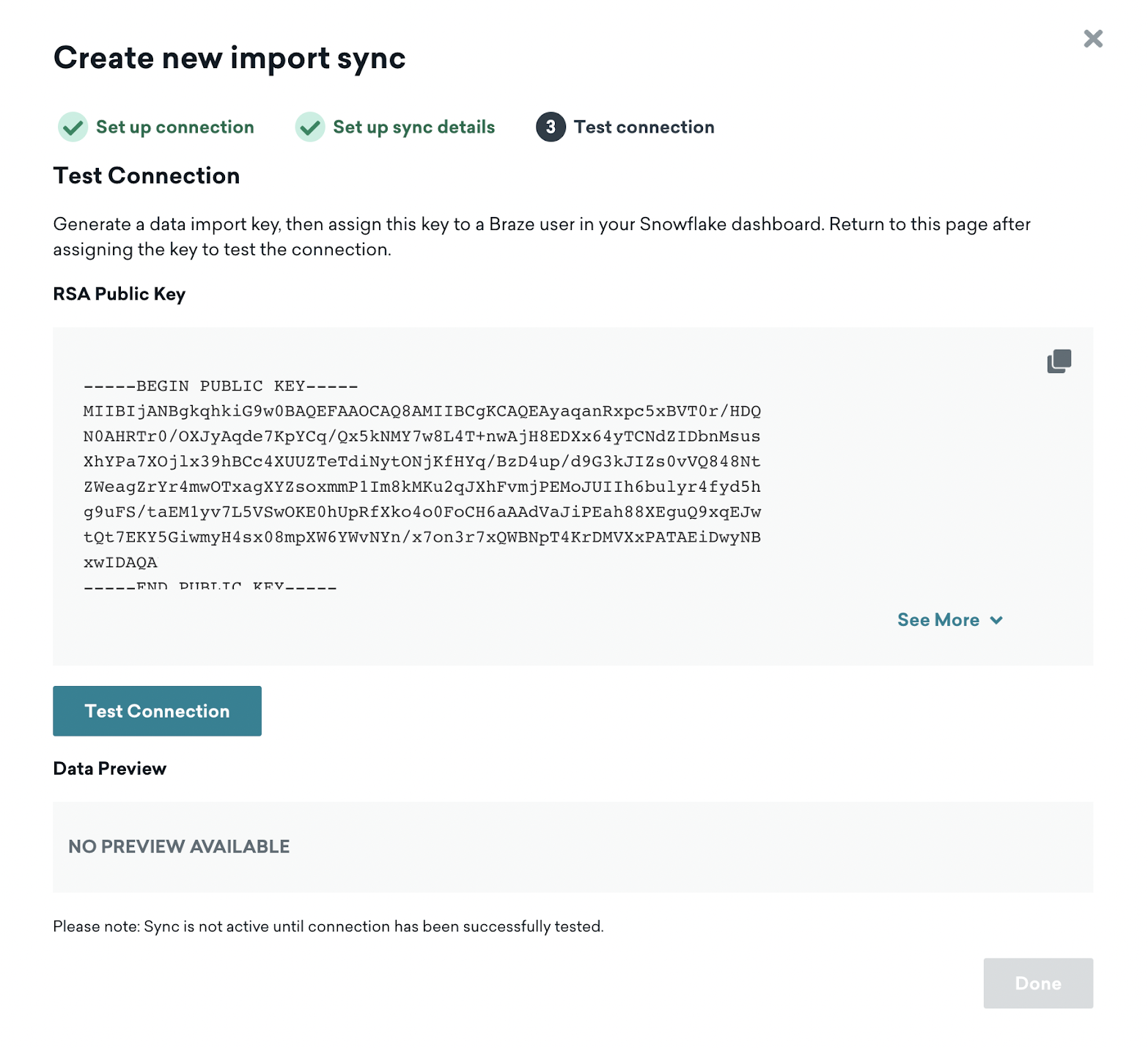
Braze ダッシュボードに戻って、[テスト接続] をクリックします。成功すると、データのプレビューが表示されます。何らかの理由で接続できない場合、問題のトラブルシューティングに役立つエラーメッセージが表示されます。
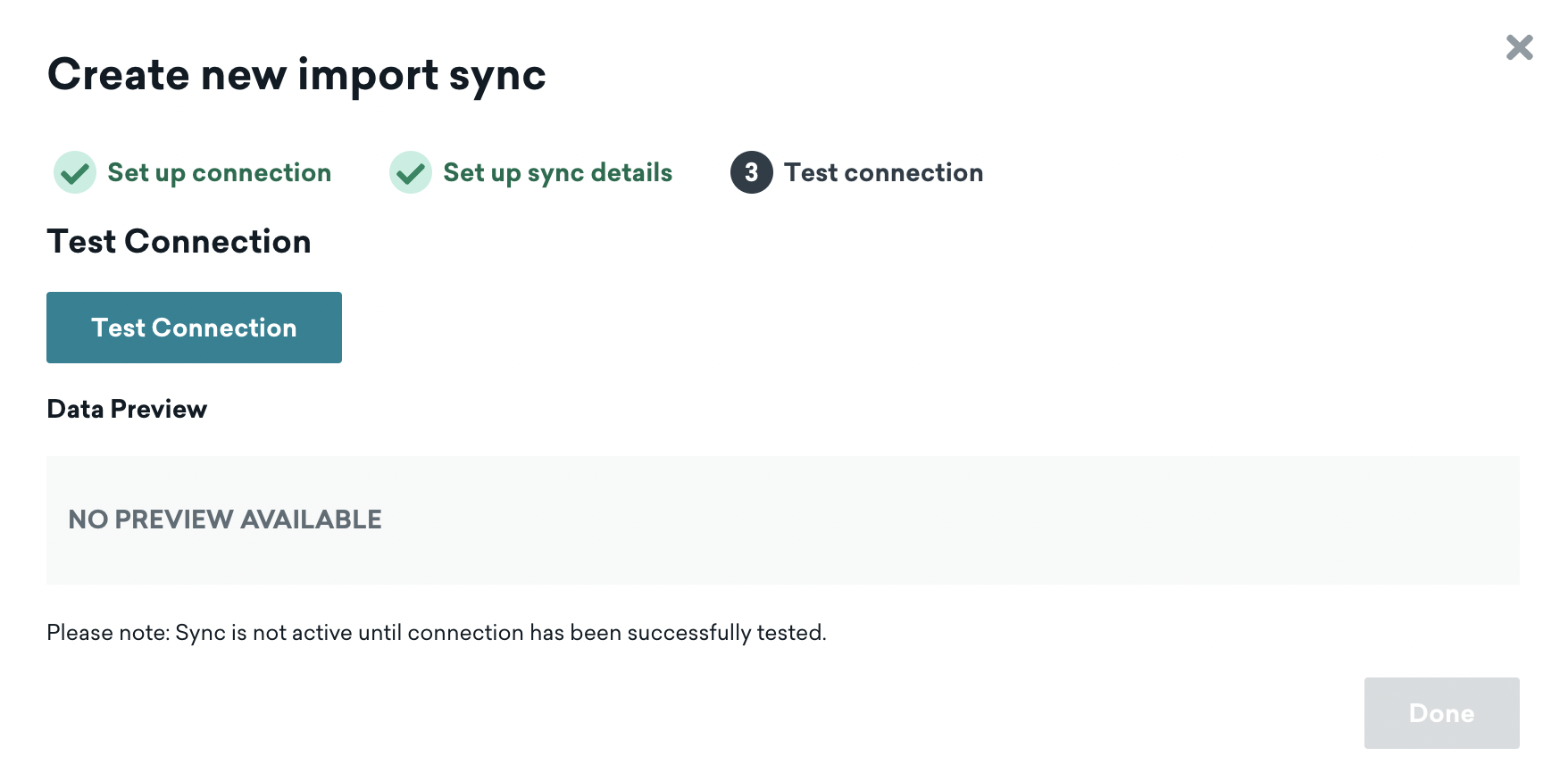
同期の設定の詳細をすべて入力したら、[テスト接続] をクリックします。成功すると、データのプレビューが表示されます。何らかの理由で接続できない場合、問題のトラブルシューティングに役立つエラーメッセージが表示されます。
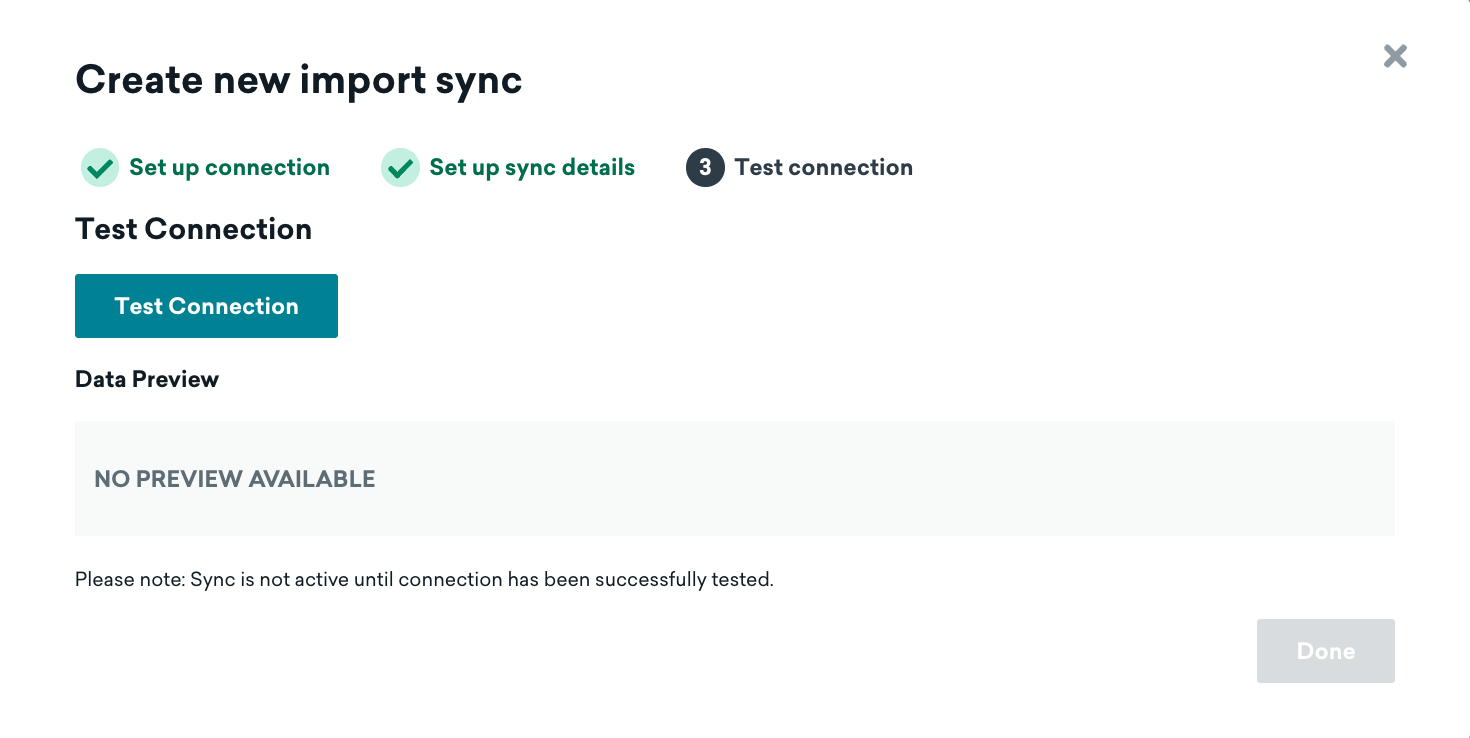
同期の設定の詳細をすべて入力したら、[テスト接続] をクリックします。成功すると、データのプレビューが表示されます。何らかの理由で接続できない場合、問題のトラブルシューティングに役立つエラーメッセージが表示されます。

連携を下書き状態からアクティブ状態に移行するには、連携のテストに成功する必要があります。作成ページを閉じる必要がある場合は、連携が保存されるので、詳細ページに再度アクセスして変更やテストを行うことができます。
追加の連携またはユーザーの設定 (オプション)
Braze との連携を複数設定することもできますが、各連携で異なるテーブルを同期するように設定する必要があります。追加の同期を作成するときに Snowflake アカウントに接続している場合は、既存の認証情報を再利用できます。
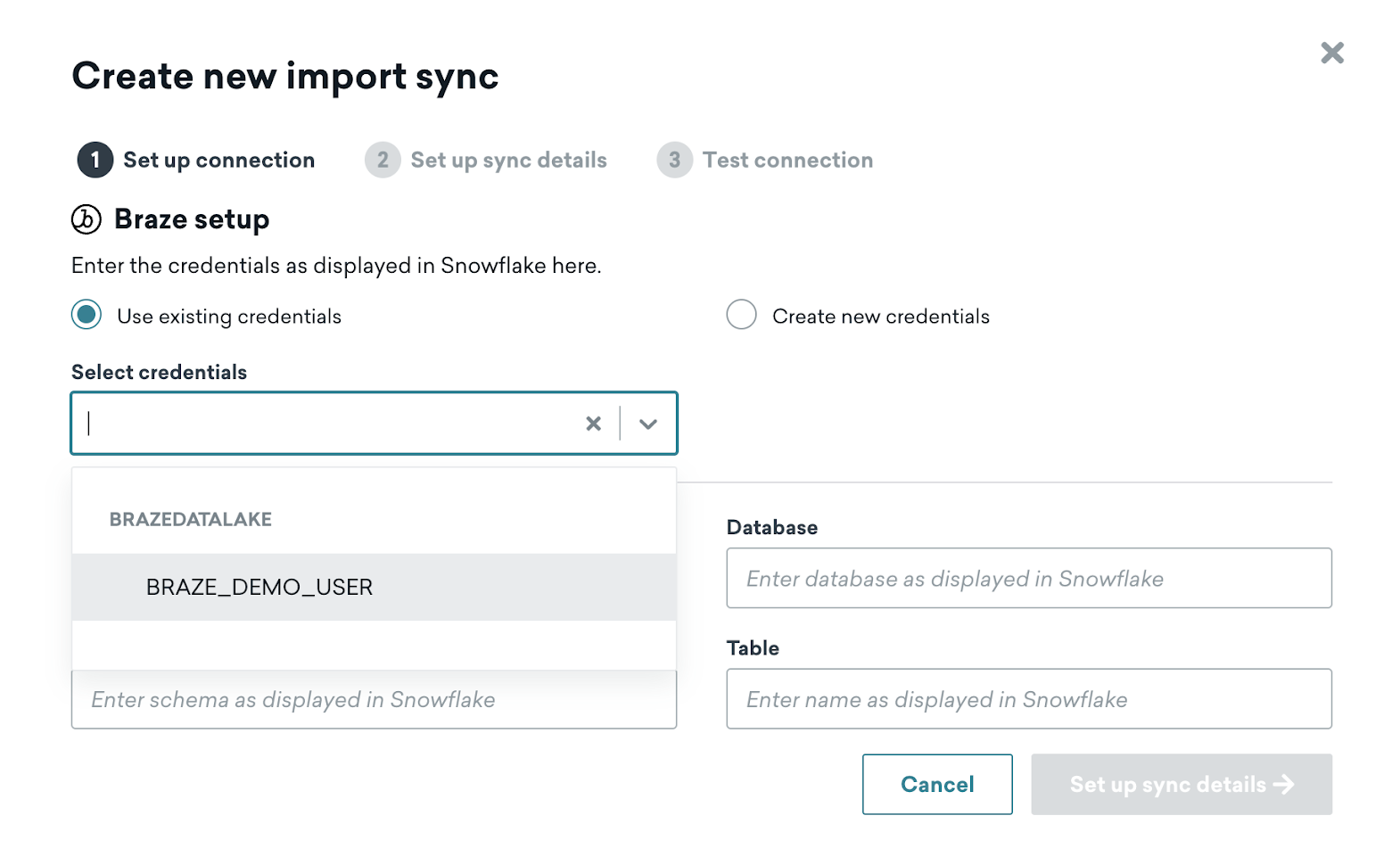
複数の連携にわたって同じユーザーとロールを再利用する場合、公開キーを追加するステップを再び行う必要はありません。
Braze との連携を複数設定することもできますが、各連携で異なるテーブルを同期するように設定する必要があります。追加の同期を作成するときに同じ Snowflake または Redshift のアカウントに接続している場合は、既存の認証情報を再利用できます。
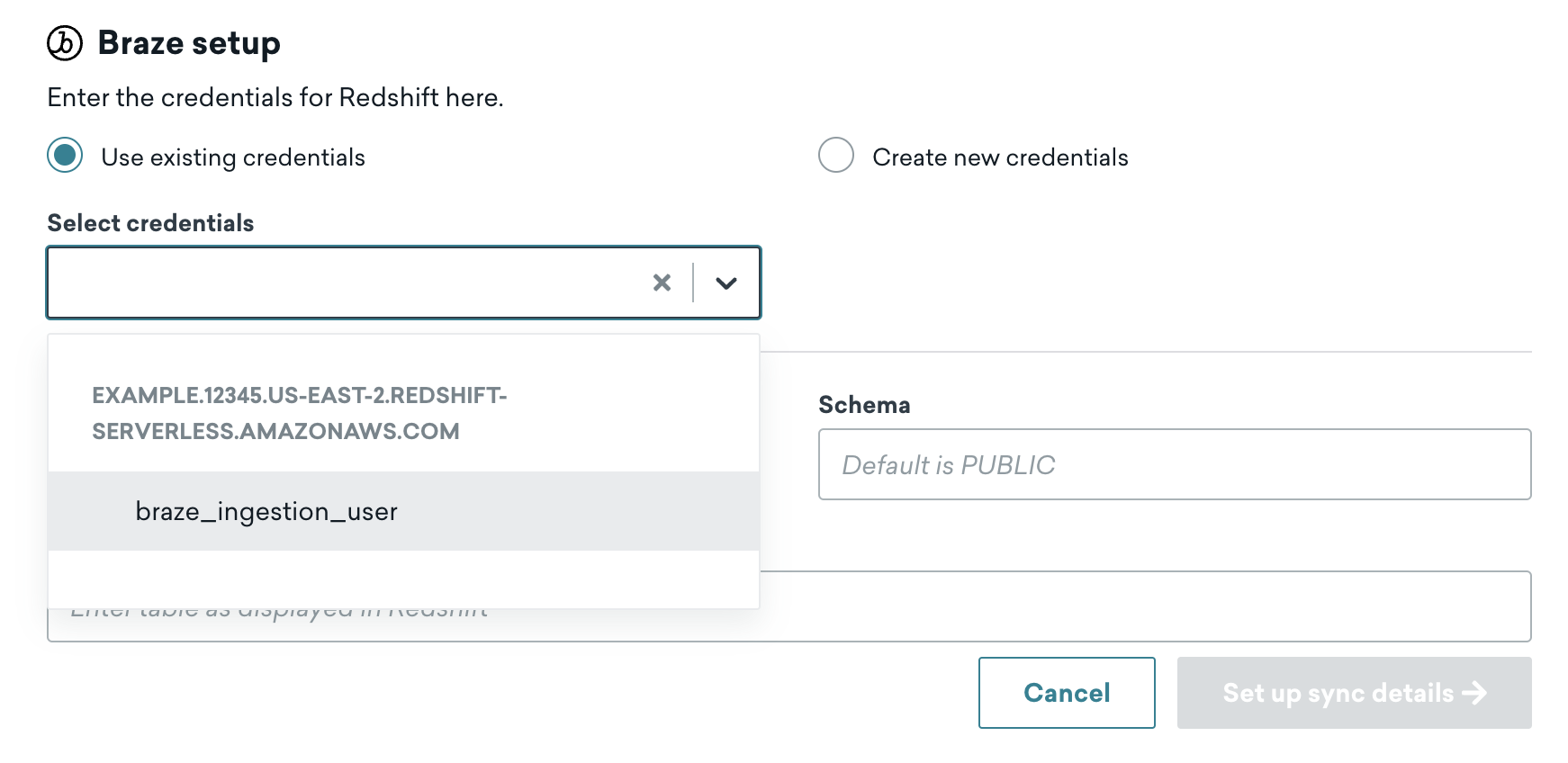
複数の連携にわたって同じユーザーを再利用している場合、すべてのアクティブな同期から削除されるまで、Braze ダッシュボードでそのユーザーを削除することはできません。
Braze との連携を複数設定することもできますが、各連携で異なるテーブルを同期するように設定する必要があります。追加の同期を作成するときに同じ BigQuery アカウントに接続している場合は、既存の認証情報を再利用できます。
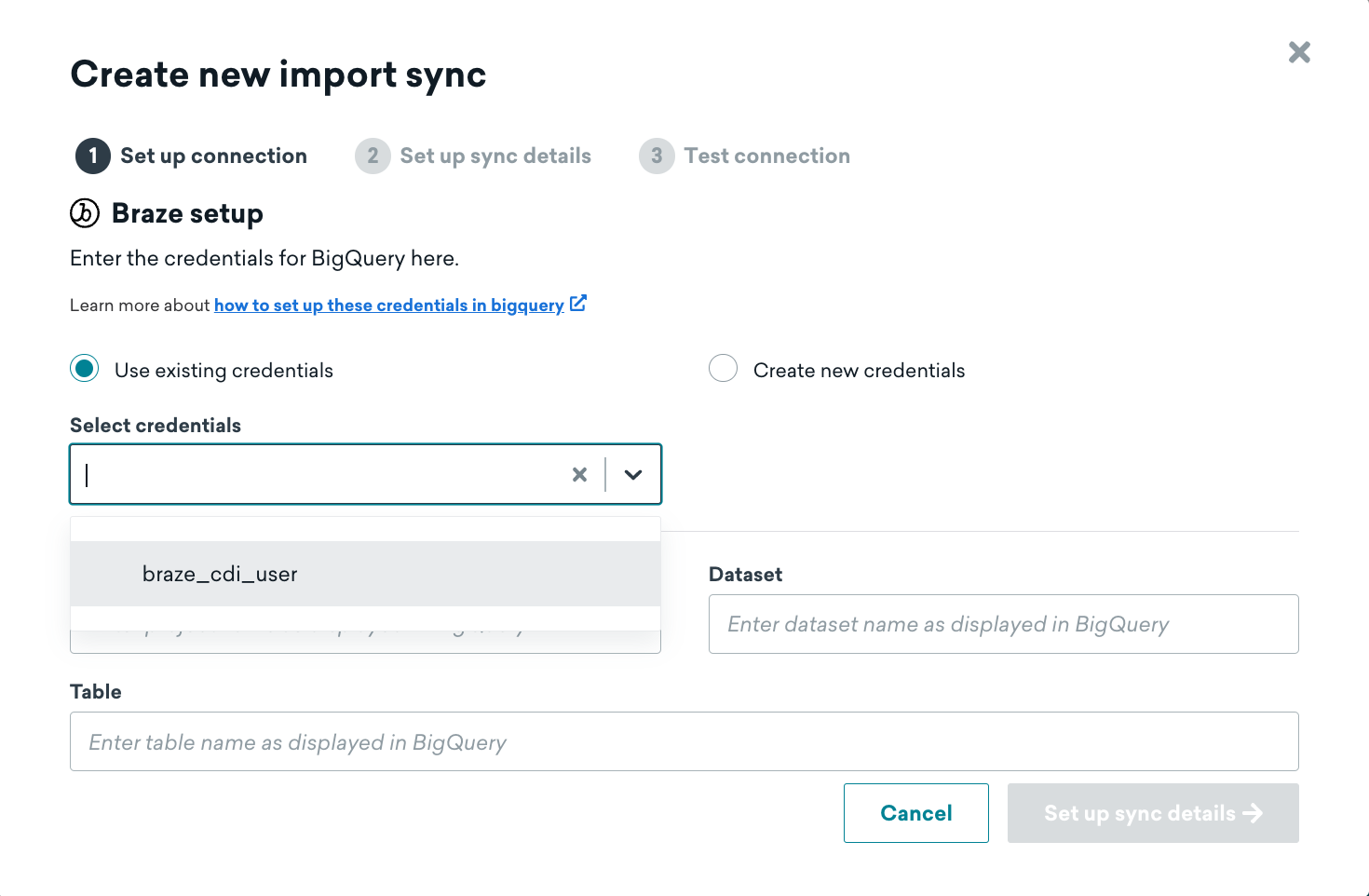
複数の連携にわたって同じユーザーを再利用している場合、すべてのアクティブな同期から削除されるまで、Braze ダッシュボードでそのユーザーを削除することはできません。
Braze との連携を複数設定することもできますが、各連携で異なるテーブルを同期するように設定する必要があります。追加の同期を作成するときに同じ Databricks アカウントに接続している場合は、既存の認証情報を再利用できます。
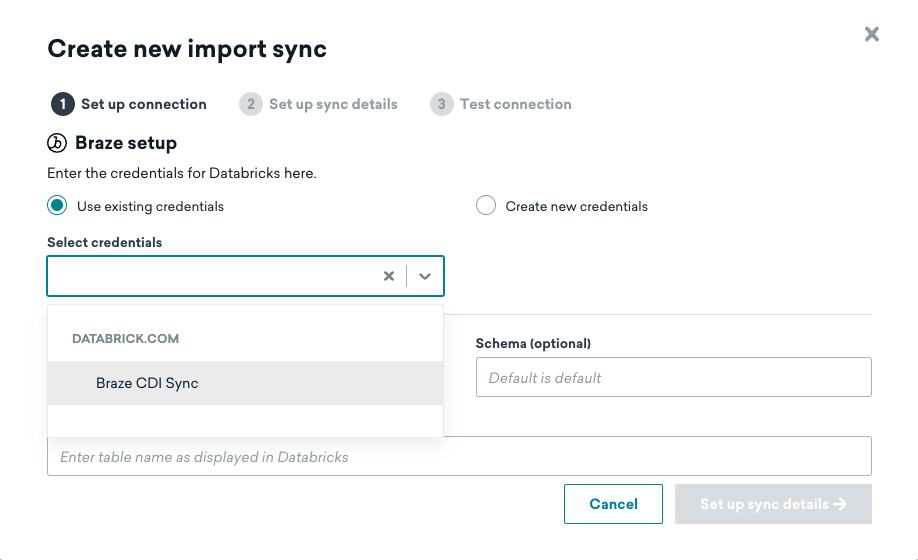
複数の連携にわたって同じユーザーを再利用している場合、すべてのアクティブな同期から削除されるまで、Braze ダッシュボードでそのユーザーを削除することはできません。
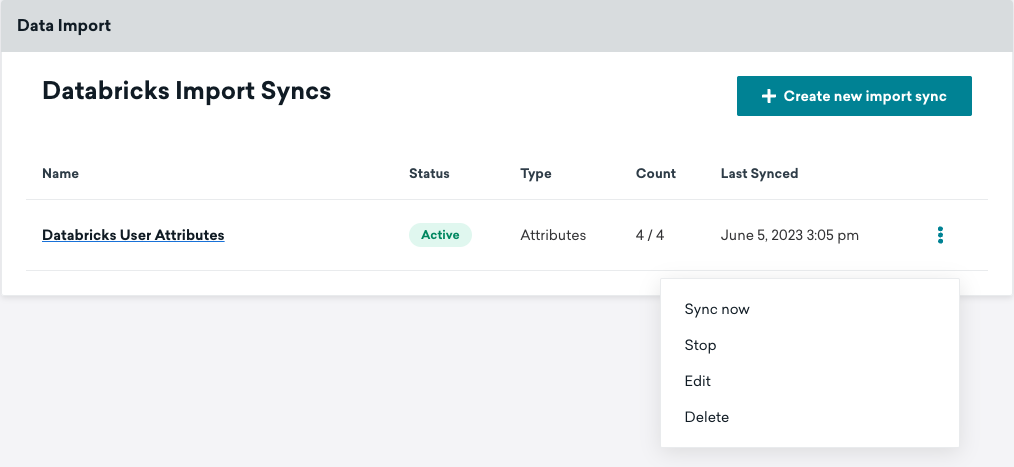
同期の実行
同期をアクティブにすると、設定時に指定したスケジュールで同期が実行されます。通常のテストスケジュール以外で同期を実行する場合や、最新データを取得する場合には、[今すぐ同期する] をクリックします。この実行は、定期的にスケジュールされている将来の同期には影響しません。
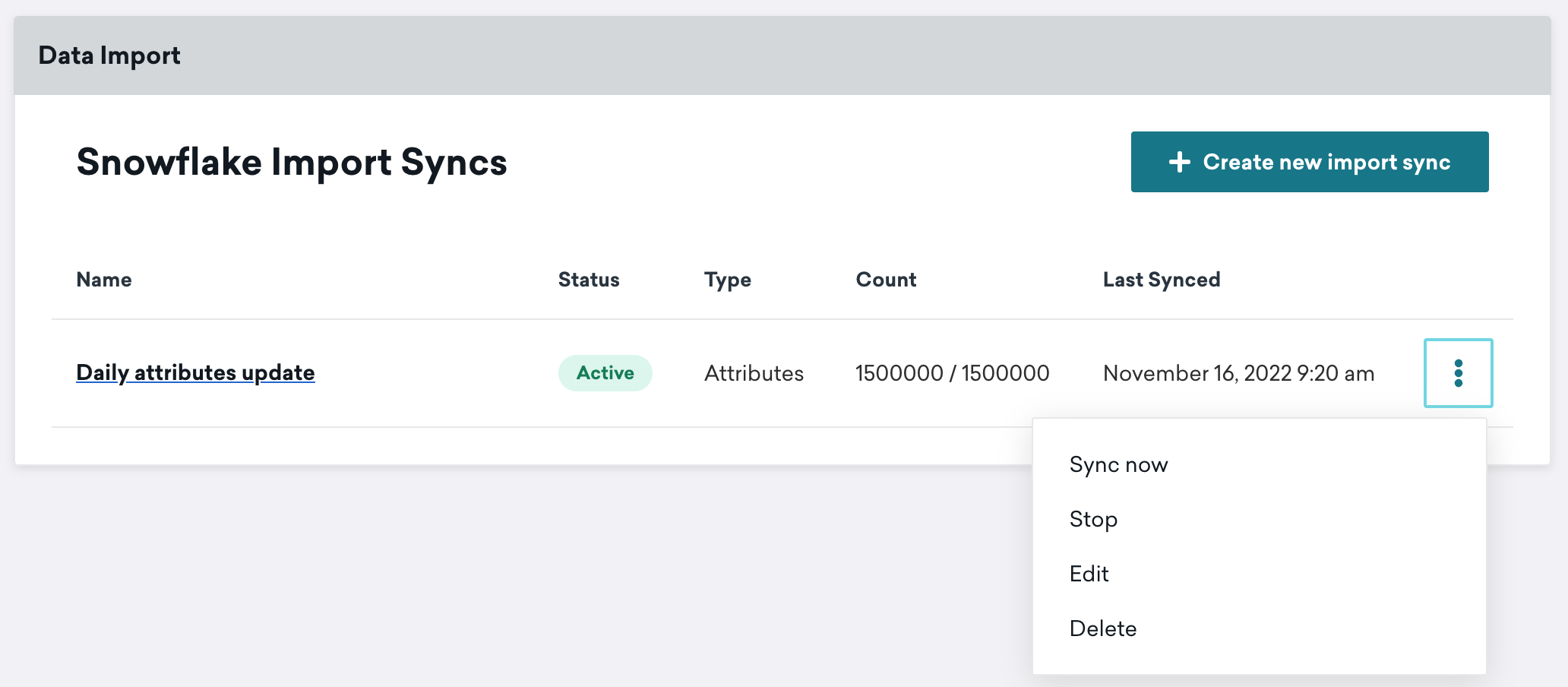
同期をアクティブにすると、設定時に指定したスケジュールで同期が実行されます。通常のテストスケジュール以外で同期を実行する場合や、最新データを取得する場合には、[今すぐ同期する] をクリックします。この実行は、定期的にスケジュールされている将来の同期には影響しません。
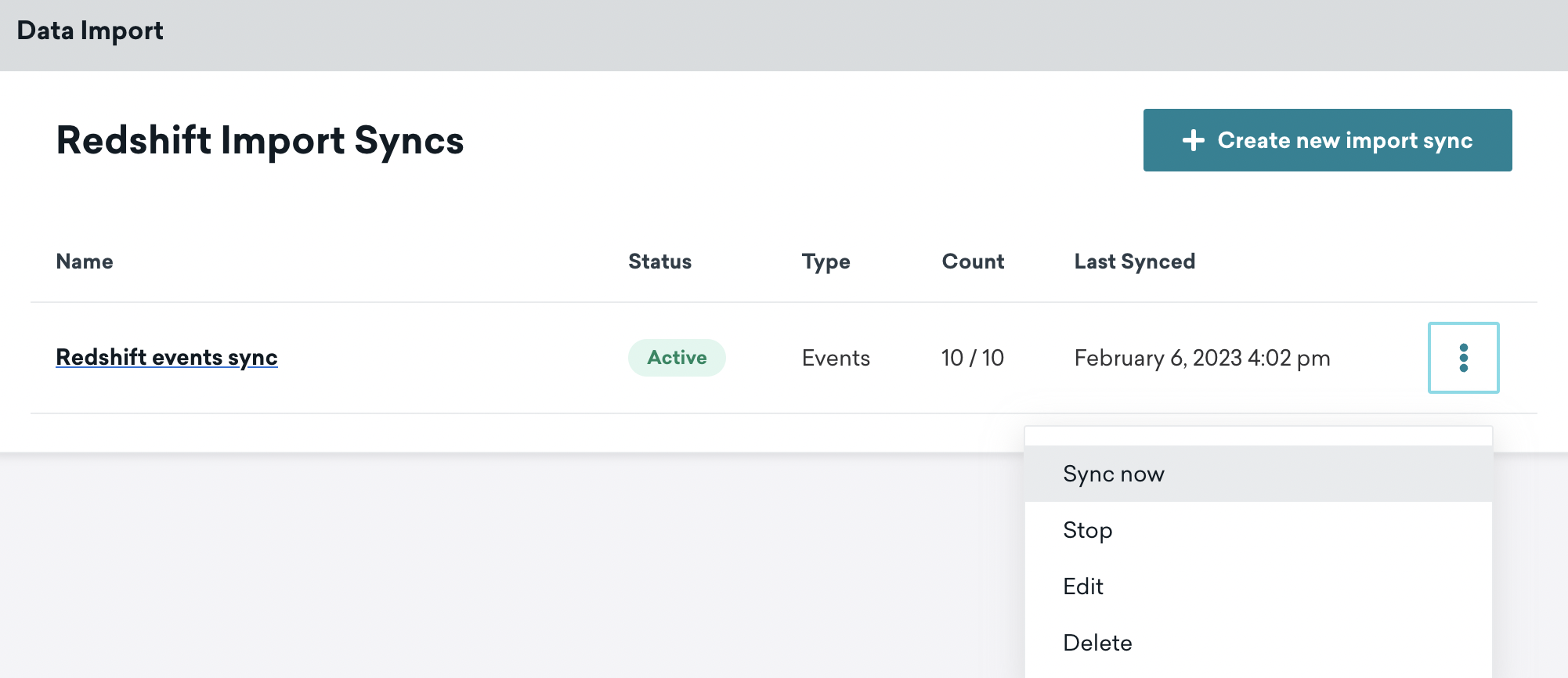
同期をアクティブにすると、設定時に指定したスケジュールで同期が実行されます。通常のテストスケジュール以外で同期を実行する場合や、最新データを取得する場合には、[今すぐ同期する] をクリックします。この実行は、定期的にスケジュールされている将来の同期には影響しません。
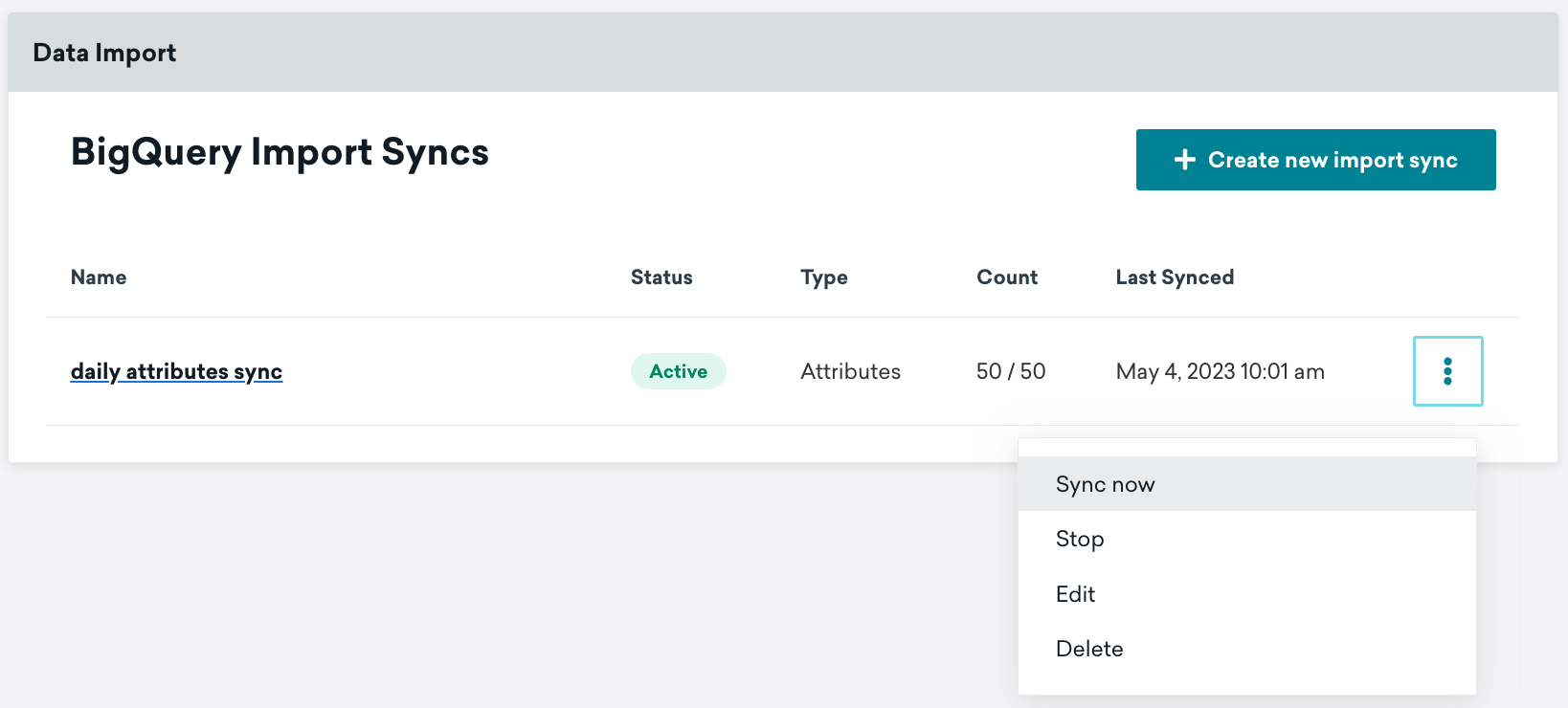
同期をアクティブにすると、設定時に指定したスケジュールで同期が実行されます。通常のテストスケジュール以外で同期を実行する場合や、最新データを取得する場合には、[今すぐ同期する] をクリックします。この実行は、定期的にスケジュールされている将来の同期には影響しません。
 GitHub でこのページを編集
GitHub でこのページを編集